About KTN
 The Knowledge Transfer Network (KTN) is the UK’s Innovation Network. KTN connects new ideas and opportunities with expertise, markets and finance through their network of businesses, universities, funders and innovators. From agri-food to autonomous systems and from energy to design, KTN combines in-depth knowledge in all sectors with the ability to cross boundaries.
The Knowledge Transfer Network (KTN) is the UK’s Innovation Network. KTN connects new ideas and opportunities with expertise, markets and finance through their network of businesses, universities, funders and innovators. From agri-food to autonomous systems and from energy to design, KTN combines in-depth knowledge in all sectors with the ability to cross boundaries.
Business Type: Non-profit Organisation
Website: https://ktn-uk.org/
Project Objectives
KTN Knowledge Graph
With decades of experience, KTN has accumulated vast amounts of valuable network data (e.g. industrial experts, academic specialists) and knowledge data (e.g. case studies). It would be useful if all these interrelated data are connected in a centralised database to provide insights into the frequency, density and efficiency of interactions between KTN contacts, and correlations between companies and experts’ specialities and interests, and due to interconnected data, a knowledge graph (i.e. using a graph-structured data model to integrate data with free-form semantics) can be used to optimally structure the data and provide analytic opportunities to KTN,
Recommender System to Support Innovators Better
One of the many ways that KTN helps innovators grow is by recommending suitable upcoming funding opportunities, events, etc. Instead of relying on a human to keep up to date with all the latest funding opportunities, events etc, or finding relevant contact in CRM, it would be more efficient and effective to use Artificial Intelligence and a Recommender System to intelligently filter information to find the most suitable requested content according to the searching criteria that utilise the centralised KTN knowledge base.
Solutions
Knowledge Graph
 The centralised database that integrates all KTN valuable data and external useful data, connected in the graph database with automated data retrieval, preprocessing and transformation.
The centralised database that integrates all KTN valuable data and external useful data, connected in the graph database with automated data retrieval, preprocessing and transformation.
The developed Neo4j database is currently primarily used to support the developed “Expert System” application as an internal tool, and it can be used to support any other application that intends to utilise the knowledge graph database, or query it to gain insight or intelligence from the graph database.
AI Enquiry Smart Analysis
The AI model that utilises information extraction (IE) and semantic filtering to analyse the enquiry content and identify the most relevant topics (e.g. artificial intelligence, agriculture) and intents (e.g. find partners, seek fundings).
The model is designed to self-learn over time when new content is generated on KTN website (e.g. new innovation field) or any other integrated database and it also allows KTN users to add and remove filtered items and thus improve filtering over time.
Intelligent Recommender System
The machine learning model utilizes Natural Language Processing techniques and word vector embeddings for semantic representation of meaning, combined with cosine similarity measure and decision making to filter through the most relevant records (from top to bottom) for the contextual topic meaning (e.g. agritech, biochemistry) in the requested content type (e.g. academic specialist, funding opportunities).
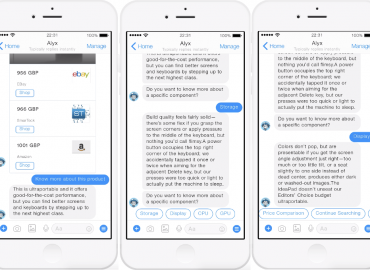
Chrome Gmail Extensions
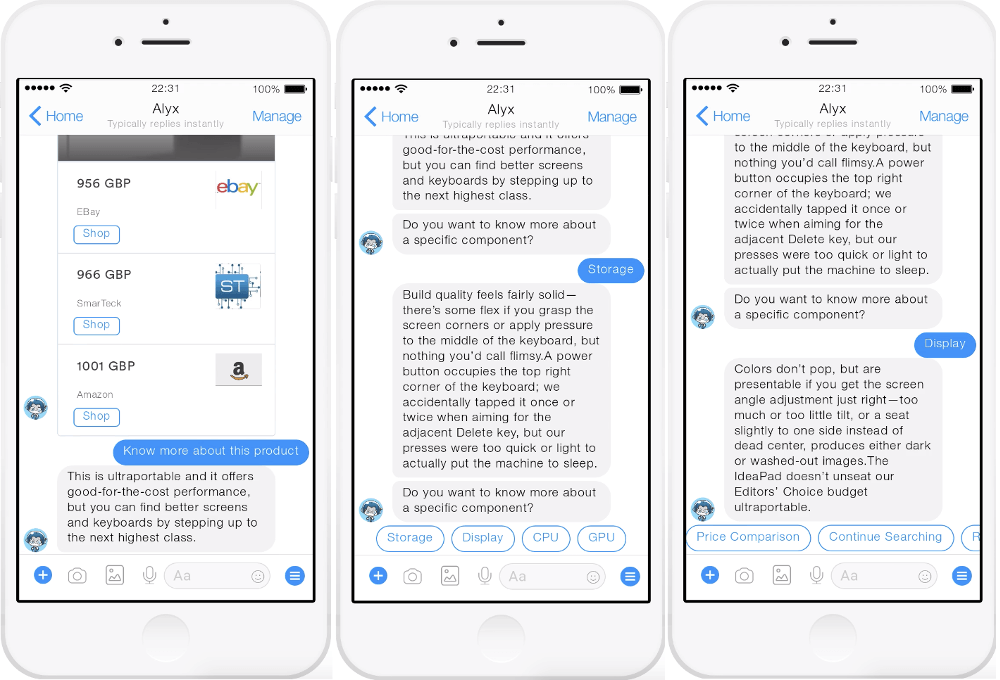
One of the Expert Systems application interface that integrates into KTM’s workflow is the Chrome Gmail Extensions that sits inside KTM’s email tool and can be used easily to analyse enquiry content, visualize the knowledge graph and interact with the recommender system to suggest the most suitable content to innovators.
Web Application
Another Expert Systems application interface is a web application that not only facilitates the same enquiry processing workflow, it also facilitates the flexible exploration of the knowledge graph.
Benefits
Consolidated KTN Knowledge Base
KTN’s valuable network and experience data along with external relevant data are integrated in the centralised graph database with interlinked relationships defined and connected, it is a powerful tool to draw insightful knowledge from.
KTM Workflow Augmented by AI Recommender System
KTMs are empowered by the AI recommender system to supercharge their workflow and find the most relevant information to help the innovators more efficiently and effectively.
Process
User Research
Our approach started with user research and interviewing various roles in KTN to provide an in-depth understanding of KTN and KTN’s workflows, and data owners and stakeholders to understand the resources and requirements for the project.
Based on the interviews, we concluded the user research materials:
- User Personas
- User Journey (current verses to-be user journey)
- User Stories (split into MVP, next phase & future phase)
In this first phase of the project, the primary user type of the application is KTM (Knowledge Transfer Manager).
Iterative Product Design, Development & Testing
Based on the user research learning, we designed a few options of Low Fidelity Wireframes (i.e. address functionality, basic organisation and task flow, but ignore graphics and details) and conducted user testing sessions to collect feedback on solution direction, including different options of functionalities (e.g. enquiry analysis, recommendation list, graphical knowledge graph) and interaction interfaces (e.g. web application, Gmail add-on).
Based on the feedback gathered from Low Fidelity Wireframes user testing, we designed the Middle Fidelity Wireframes (i.e. address lo-fi concerns, plus layout, interactivity and navigation, but ignore graphics, real data) on the confirmed main functionalities and user interfaces. In the Middle-Fidelity Wireframe user testing sessions, we improved the graph in order to make it easy and clear to use.
Following the Middle Fidelity Wireframes user testing analysis, we designed the High Fidelity Wireframes (i.e. address mi-fi concerns, plus graphic design, interaction details and realistic data, but ignore programming and complete functional coverage) that integrate the KTN branding styles In the High Fidelity user testing sessions, we identified opportunities to change the knowledge graph display and editing options that help users interact with the graph more intuitively.
After the High Fidelity Wireframes were confirmed, back-end developers started developing the endpoints that facilitated the functionalities and front-end developers developed the user interface and integrated the back-end endpoints.
Once the first version of the application was developed, we conducted Alpha Testing with users who could potentially be Power Users to further understand the usability and functionality of the application.
Data Engineering
1. Data Centralization
Internal data sources (e.g. KTN website content, CRM) and external data sources (e.g. UKRI, Cordis) were modelled, structured and loaded into the Neo4j graph database.
2. Deduplication & Consolidation
Same records (e.g. person, company) can appear duplicated in the same data source or across multiple data sources, while at the same time certain records might have similar properties the same name, therefore, we developed advanced data profiling techniques to duplicate and consolidate records across data sources.
3. Automatic ETL Pipeline
In order to ensure that the system receives up-to-date data (e.g. new funding opportunities, outdated events), we developed an automatic ETL (Extract, Transform and Load) data pipeline that applies all the required data transformation steps before injecting data to the database.
Data Science Development
KTN Innovation Corpus and Word Embeddings
KTN innovation corpus consists of tokens that represent the entire KTN knowledge domain. The textual content across KTN resources is used to prepare the innovation corpus that is represented by sentences converted to a list of tokens. Very frequent pairs of tokens are joined into phrases to make sure the model will recognise phrases such as ‘artificial intelligence’ with higher accuracy. Once the innovation corpus is prepared, it is further used to train Word Vector Embeddings using the Gensim approach.
Information Extraction using Word embeddings
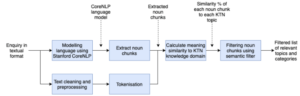 The purpose of information extraction (IE) is to extract topic key phrases that are closely related to the KTN knowledge domain, and content categories that indicate the demands of the end-users.
The purpose of information extraction (IE) is to extract topic key phrases that are closely related to the KTN knowledge domain, and content categories that indicate the demands of the end-users.
Information extraction was validated using a supervised approach, where human domain experts and data scientists labelled content with most significant and KTN knowledge domain related key phrases. The human made labels were used to compare with noun chunks extracted by the methodology.
AI Recommendation Search
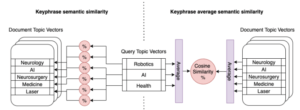 AI recommendation uses semantic search to find suitable content entries for the specified semantic meaning provided by a set of keywords and phrases. When using semantic search, one of the main questions is whether to use average meaning by averaging vectors for all keywords, or perform keyword by keyword semantic comparison and use rule based logic for decision-making on which content entries to finally recommend. The concept is shown schematically in the below figure, where left side shows a case when we use individual keyphrases from the input query and compare them semantically with individual key phrases extracted from each document, and select documents using rule based approach based on how many and how well keyphrases matched. Alternatively, the right side shows a case, when we use averaged semantic search and first average word vectors and calculate a single similarity to be able to decide whether or not to recommend a document.
AI recommendation uses semantic search to find suitable content entries for the specified semantic meaning provided by a set of keywords and phrases. When using semantic search, one of the main questions is whether to use average meaning by averaging vectors for all keywords, or perform keyword by keyword semantic comparison and use rule based logic for decision-making on which content entries to finally recommend. The concept is shown schematically in the below figure, where left side shows a case when we use individual keyphrases from the input query and compare them semantically with individual key phrases extracted from each document, and select documents using rule based approach based on how many and how well keyphrases matched. Alternatively, the right side shows a case, when we use averaged semantic search and first average word vectors and calculate a single similarity to be able to decide whether or not to recommend a document.
Technologies Used


![]()

About the Project
We developed an AI-powered Expert Systems solution for Knowledge Transfer Network (KTN) to enhance KTN managers workflows to help innovators more efficiently and effectively. The solution includes: a centralised graph database integrated with KTN’s network and experience data enriched with insights from external research projects and publications data (e.g. UKRI, Cordis); a machine learning (ML) and natural language processing (NLP) module with enquiry analysis tool and intelligent recommendation system; and a Gmail Chrome extension and a web application facilitate the visualization and interaction with the knowledge graph.
Client
KTNRelated Projects
Sed arcu. Cras consequat.






{kind=link}
{kind=link}
{kind=link}